「型 'JSX.IntrinsicElements' に存在しません」エラーについて
概要
最近記事を書いていなかったので、ちょっとした備忘録を。 定期的にやってしまいがちなので、忘れないように形にして残しておきます。
タイトルのエラーについて
一言で言うと、JSXのコンポーネントは大文字から始めるようにしましょう。 小文字の場合、React がコンポーネントだと認識せずに、HTML タグだと認識してしまいます。
以下の例を見ていただけると分かりますが、コンポーネント名を変えるだけで、エラーを解消することができます。
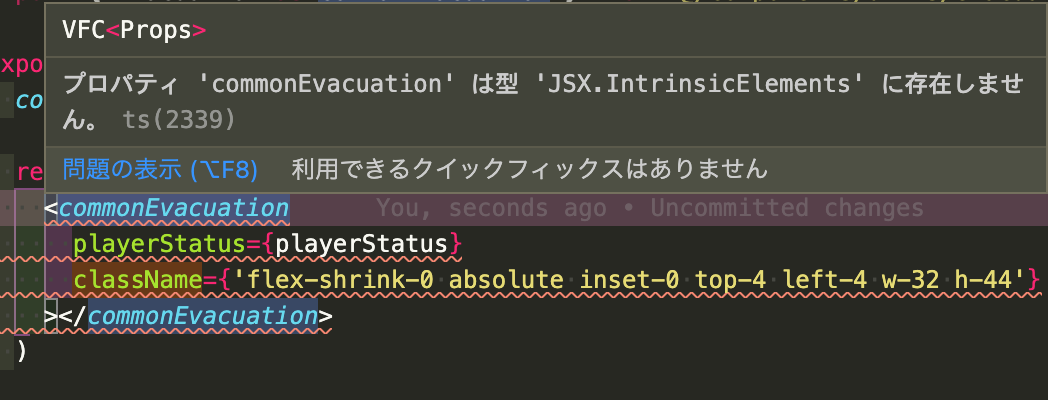
⇨

詳しくはReactの公式ドキュメントに書いてありました。
ある要素の型が小文字から始まっているような場合、それは
CSスタッフがより良い文章作成を目指してサービスを開発しました(制作背景編)
本記事では、CSスタッフがより良い文章作成を目指してサービスを開発しましたについて、技術以外の内容をお話しいたします。
今回は、私が開発したサービスの制作背景や、課題解決に対する考え方、良い文章に対する考え方を書いてみました。 あくまで私の経験や考え方を紹介できればというつもりですので、決して正しいことだけを論じているわけではないことは、お含みおきいただけますと幸いです。
自己紹介
はじめに、少しだけ自己紹介をさせていただければと思います。
私は元々エンジニアとしてIT系の会社に新卒で入社しました。 半年後に所属チームが変わり、そこから約1年は主にCSスタッフとして働いています。
少しだけエンジニアの知識があるCSスタッフというのが、私の立ち位置です。
制作背景
今回サービス開発をはじめたのは、私の持つ少ない技術を駆使して、CS業務に活かせるものが作りたかったからです。
実は過去にも何度か同じトライをしてみたことはあるのですが、上手くいかないことばかりでした。 原因として、技術レベルとドメイン知識不足というのもありますが、それ以上に表面的な課題だけを解決しようとして、本質的な課題を見抜けていなかったことが大きいです。
例を挙げて話してみます。
職場に大量のデータを手入力で処理するのが大変だと困っているAさんがいると仮定します。 このAさんに対して、データを一括で処理するスクリプトを作成してあげることは、課題を解決したことになるでしょうか?
私はNoだと思います。 確かに、一時的には作業を簡略化できます。 しかし、データ形式の変更等でスクリプトが動かなくなってしまうと、また手入力に逆戻りです。
本質的な課題解決のためには、そもそもこれはAさんがやるべき作業なのかと前提を疑ってみたり、スプレッドシートなど比較的学習コストが低いツールの扱い方を教えて、Aさんに「大量のデータをデータを処理する手段」を身につけてもらったりする考え方が必要です。
(クリティカルシンキングの考え方が非常に参考になります。)
この課題解決に対する考え方は、CS業務の中で身につきます。 日々多くのお客様と向き合う中で、文面だけではなく、裏側にある感情や課題について考えるようになります。
個人的には、お客様の本当の気持ち、本当に求めているものを理解することこそ、「良いCS」だと思っています。
話が逸れてしまいましたので、そろそろ本題に入ります。
私の業務では文章作成をする時間が一番長いので、何か文章作成に役立つツールを作ろうとしてみました。 真っ先に思いついたのは、文章のミスをチェックする校正ツールです。
しかし、ツールによって文章のミスをなくすというのは、表面上の課題を解決しただけになってしまいます。 ツールを使ってくれた方がミスのない文章を書けるようになったとしても、あくまでツールの使い方を学んだだけになってしまうのではないでしょうか。
仮にその方がツールを使わなくなった時に、チェックなしでは文章ミスを生み出してしまうようでは、本質的な課題を解決したとは言えません。 (私自身、普段VSCodeで自動保存時にlintが走ることに甘えていて、一度何も入れていないVimを使った時にlint違反だらけのコードを生み出してしまった経験があります。)
また、一人でツールの保守運用に責任を持ち続けなければいけないのはしんどいですし、組織的にもあまり好まれないです。
本質的な課題解決としては、ツールなしでもミスのない文章を作成できるようになってもらうのを目指します。
今回思いついたアイデアは、ただ文章をチェックするだけではなく、校正結果の記録を取って、後から振り返れるようにする仕組みです。 記録した改善点を分析して、自分の文章の癖やどんなミスが多いのかを発見し、文章作成能力そのものを向上させるサポートができればと考えています。
私の「良い文章」に対する考え方
私が考える「良い文章」は、読みやすい文章です。
ここまで書いてきてなんですが、文法ミスや誤字脱字のない正しい文章であっても、読み手に理解して貰えなければ良い文章ではありません。 個人的には、読み手への配慮は人間にしかできなくて、まだまだAIやツールでは代用できないことだと思います。
もちろん、だからといって文章の正しさを軽視していい訳ではありません。 せっかく読み手に寄り添って書いた文章であっても、ちょっとした文法ミスによって、正しく伝わらないかもしれません。 読み手への配慮とミスのない正しい表現は、両方とも「良い文章」に欠かせない要素なのです。
文法ミスなどの機械的なチェックはシステムに任せて、人間は人間にしかできない読み手への配慮により集中することが、「良い文章」を書くための最短距離になるのではないでしょうか。
おわりに
ここまで読んでくださりありがとうございました。
もし興味を持ってくださった方は、元記事の方もご覧いただけますと嬉しいです。
プロ野球速報的なことをするためのAPIを作った話
はじめに
先月の私は、小さいアウトプットを重ねようと決意していました。 今月の私は、手を動かしてモノ作ってるとそちらに夢中になって全くアウトプットが出来ていませんでした。
不思議です。
作ったモノ
タイトルの通り、プロ野球の試合情報(打席結果)を返すAPIです。 実際に完成したコードはこちらに置いています。
大まかなイメージとしては、以下の図のようになっております。
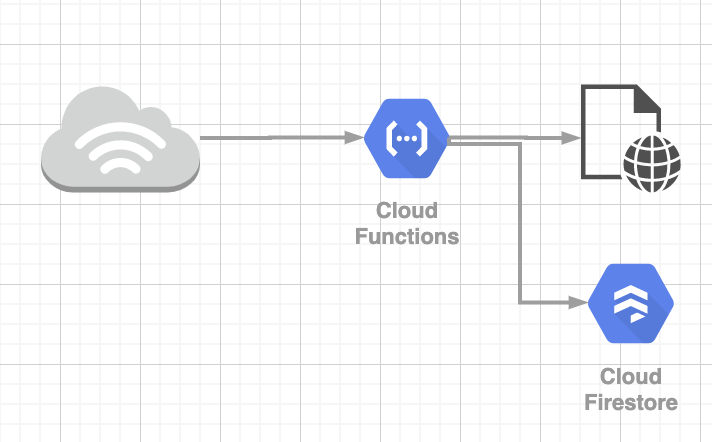
- CloudFunctionsでHTTPリクエストを受け取る
- パラメータを基にニュースサイトからスクレイピングしてデータを拝借
- 打席結果をJSONで返す
- この時、パラメータとデータをFireStoreに保存し、次回同じリクエストの際にはスクレイピングせずに保存したデータを用いる
とても恐縮なのですが、データ提供元の権利関係が怖いので、エンドポイントの方は公開しておりません。*1
一応調べたところ、robots.txt というクローラー関連の規約があるようです。
しかし、私が今回拝借したサイトにはこのファイルが置いてありませんでした。
その場合は、目安としてアクセス間隔は1秒以上空けるようにするのが良さそうです。
このアクセス間隔の制御については、API側では行っておりません。APIを呼ぶクライアント側が持つべき責務と考えたのですが、実際のところどうなんでしょうか...? この辺りの考え方はまだまだ勉強しなければと思ってます。
苦労したところ
スクレイピングについては、BeautifulSoupのライブラリがとても使いやすいのでほとんど苦労しませんでした。 一番大変だったのは、PythonでFireStoreとのデータをやり取りする部分です。
FireStoreにデータを保存する場合、基本的にDictionaryのデータ構造に整形する必要があります。このデータ構造の違いを吸収させるのが結構大変です。それなので、データクラスを作ってそのクラスにデータ変換をするto_dict の処理を任せることにしました。
@ dataclass
class Result:
team: Team
date: Date
content: Content
def to_dict(self):
dest = {
u'team': self.team,
u'date': self.date,
u'content': self.content.to_dict(),
}
return dest
また、こういったデータクラスを作るならと思い、後からFireStore以外のデータソースにも変更できるように、Repositoryパターンを使ってみました。 今回のミニマムな設計だとそこまで画期的な効果はないですが、より複雑な設計のアプリであればこういった設計力が生きてくるのかと思います。
class ResultReposiroty:
def __init__(self):
db = firestore.Client()
self.collection = db.collection('result')
def save(self, result: Result):
self.collection.add(result.to_dict())
def update(self, result: Result):
doc_id = self.collection.where(u'date', u'==', result.date).where(
u'team', u'==', result.team).get()[0].id
self.collection.document(doc_id).update({u'content.record.texts': result.to_dict()
[u'content'][u'record'][u'texts']})
def find(self, date: Date, team: Team):
docs = self.collection.where(u'date', u'==', date).where(
u'team', u'==', team).get()
return docs
まとめ
最初はGraphQLを使ってみたいと思ってたのですが、以下の理由により断念しました。
- 元々エンドポイントが一箇所なので、GraphQLの旨味が少ない
- フィールド数も少ないし、階層データも少ない
- pythonのGraphQLライブラリ
GrapheneをFireStoreと繋ぎこむのが難しい- pythonのORMモジュール
SQLAlchemyがFireStoreに対応していない
- pythonのORMモジュール
他にも、スクレイピングでテストやCIはどうするのか等々、正直途中で辞めたくなったレベルなのですが、完成させないまま投げ出すのは良くないと思いとりあえず見せれる段階までは作りました。 次作るモノは、初期設計から念入りにやっていこうと思います。
*1:個人用途で使う分には侵害にはならないようです。どこまでがセーフか分からなかったので、安全な方に倒させていただきました
一人slackのすゝめ
はじめに
多くの方はご存知かもしれませんが、slackはIT企業などで使われているコミュニケーションツールです。 slackは「ワークスペース」という単位でグループ分けされていて、通常一つの会社やチームは一つのワークスペースが作られています。
このワークスペースは、個人でも簡単に作成することができます。 今回は自分用のワークスペースを作って、そこで一人slackをするのが色々と便利という話です。
ちなみに、思いついた時は神アイデアかと錯覚していたのですが、調べてみると割と同じようなことをやられている先駆者様は大勢いらっしゃいました。
使い方
使い方はとてもシンプルです。自分の思ったことや調べたこと、やったこと等々、なんでも好きなことを書くだけです。
自分は勉強してる時にはエラーコードごと貼り付けたり、読書する時には感想を雑に書き殴ったりしてます。何でしたら、何時までこの本を読むといった自分の予定を言語化することで、宣言通りに動くようにするといったマイルールを作っているくらい自由です。
一例としてはこんな感じです。
(基本的に人に見せるものではないので、汚い言葉を使っている点はご容赦ください🙇♂️)


やってて良いなと感じてること
メリット① アウトプットの前に見返すことができる
アウトプットの大切さは十分理解したつもりなのですが、それでもアウトプットする内容がなかったり、できそうな内容を忘れてしまったりすることは多々あります。
そこで、分かりやすい言語化はできないけどとりあえず覚えておきたいことや、アウトプットするほどではないちょっとしたことなどを書き溜めておきます。 これを見返すことで、アウトプットできる内容を探しやすいですし、インプット直後の自分の気付きを失わずにすみます。
メリット② インプットの目的を明確にできる
先日書籍から得た学びですが、インプットの目的である「何を知りたいか」を言語化することで、インプットの効率は上がります。
私は実践方法として、「何を知りたいか」を実際にslackに残すようにしています。 これをすることで、書籍を読んでのTODOが実践できているかを振り返る仕組みにしようと思います。
メリット③ 同じことを繰り返さないで済む
上の画像にもありますが、試したことからエラーログまでできるだけいろんな情報を残しているので、後から同じエラーが起きた時に解決手段をすぐに追うことができます。 これまで、「過去に同じようなエラーを見たけどどうやって解決したか忘れた」「前にこれやろうとして断念したけど、何で断念したのか忘れた」といった同じ失敗を繰り返すことが多い自分への戒めです。
改善点
一つはっきり思っているのが、スレッドにまとめることです。 いくらslackの優秀な検索機能があるからといっても、量が増えすぎるとどうしても後から追いにくくなってしまいます。
ほかにも色々と改善できるとことはありますので、随時改善していこうと思います。
まとめ
正直、「Twitterで良くない?」「メモ帳でも良くない?」と言われたらその通りだと思います。自分は、スマホや会社のPCからもアクセスしやすかったり、ほかにRSS通知やbotなどの連携が便利だったりという理由で、Slackを選んでいるだけです。
要は、言語化して自分の考えをはっきりさせることや、過去から振り返れるように記録を残すことが大事ということです。 そのための手段は、各々が自分にあったものを選んでいくのが良いと思います。
読書録「学び効率が最大化するインプット大全」
はじめに
先日読んだ「学びを結果に変えるアウトプット大全」に続けて、「学び効率が最大化するインプット大全」を読みました。 同じ著者の方が出版しているインプットについての書籍です。
効率の良いインプットのやり方やどんな情報をインプットするべきかなどが、著者の日常生活やエピソードを交えた説明のおかげでわかりやすく学ぶことができました。
感想
本を読む前の「ビフォー」として、目的を3つ決めてからインプットに挑む重要性が説かれています。 冒頭でこの章を読んでから、今回学ぼうとした情報を改めて考え直してから次の章へと読み進めました。
- どうすれば効率の良いインプットができるか
- どうすればインプットをアウトプットに繋げられるか
- どういった情報をインプットするべきか
効率の良いインプット
この問いに対する回答として、最初に行った3つの目的を決めておくというものが、一番に挙げられます。 目的を決めることで「カクテルパーティー効果」(ガヤガヤしたパーティでも自分の名前が呼ばれた際にはすぐに気がつける働き)が有効になります。 また、質問にして自分に問いかけることで、自然と答えを探すようになります。
個人的に思いついたこととして、目標を決めたあとそれを5W1Hのどれに当てはまるかも決めておくという手法を実践してみることにしました。(これは書籍内の情報ではないので信憑性はありません、あくまで自分なりのやり方です)
- どうすれば効率の良いインプットができるか => How => 方法を探そう!
- どういった情報をインプットするべきか => What => 「もの」「こと」を探そう!
ほかにも、具体的なテクニックがいくつか見受けられましたが、一度に大量の学びを得ようとするより3つの気付きを得ようといったことも書かれていたので、まずは目標を決めてインプットすることを習慣づけてみます。
インプットをアウトプットに繋げる
この内容については、明確な回答としては見つけられませんでした。おそらくですが、アウトプット前提でインプットすることが強く言われているので、ここで大切なのはインプットの意識ではなくアウトプットの意識なんだと思います。
強いてあげるなら、メモやノートを整理することなど、インプットをその場で終わらせないことがコツなのかもしれません。
どういった情報をインプットするべき
この問いに対する回答は明確に挙げられます。「3点読み」です。
「3点読み」とは、「賛成派」「反対派」「中立派」の異なる立場から書かれた情報をインプットすることです。人間どうしても先入観や偏見から偏ったインプットをしてしまうものなので、バランスをとった情報をインプットすることが大切です。
実際、自分が調べものをする際は、既に自分の中で答えが決まっていてそれを裏付けてくれる情報を探してしまうことが多いです。 例えば、iphone12を買いたいと思ったので「iphone12」で検索すると、自然とiphone12の良いところばかり書かれた記事を見てしまいます。 このような偏見をなくすためにも、「iphone12 デメリット」などの内容で検索し、反対派の情報も探すべきです。
まとめ
今回のTODOとして、「何をインプットするか」の目的を決めてからインプットに挑むことをやってみます。とはいえ、このTODOが実践できているか振り返るのは難しいため、解決策として一つ試していることがあります。 この試みについてもそのうち書こうと思います。
読書録「学びを結果に変えるアウトプット大全」
はじめに
アウトプットの重要性やそのやり方、なぜするべきかについて学べる「学びを結果に変えるアウトプット大全」を読みました。 本書籍でおすすめのアウトプット・トレーニングとして「読書感想文を書く」ことが挙げられていましたので、早速試してみようと思います。
読書感想文のテンプレート
「ビフォー」+「気付き」+「TODO」
これが10分で読書感想文を書けるようになるテンプレートです。 感想を話すときは事実だけでなく、「自分の意見」「自分の気付き」を書くことが重要です。
実際に書いてみる
【ビフォー】
私はアウトプットに対してハードルが高いと感じていて、なかなか行動することができませんでした。人のためになる情報を書けるのか自信がなく、せめて情報量を増やそうとしてしまうことばかりでした。
【気付き】
この本を読んで、最初から長い文章を書こうとするから、だらだらと時間を決めずにやってしまうと気付かされました。よく考えてみると、これは設計を考えずにコードを書いたあと結局リファクタリングの手戻りが多発するエンジニアと、ある意味近いところがあるのかもしれません。
そして、この本にはこうも書かれています。
- 制限時間を決めて取り組むことで効率が高まる
- 1日15分、1アウトプットからスタート
- 3行でいいから毎日続ける
- 量や質を目指すよりも、毎日続けることが最も重要
いきなり、常に有益な情報を発信するような方レベルの文章を書けるわけもありません。まずはアウトプット癖をつけることが一番大事だと学びました。
【TODO】
これから、毎日朝の15分をアウトプットの為の時間に割り当ててみます。 実際に毎日アウトプットを記事にするのは難しくても、1日3行を積み立てるようにしていれば、少しずつ頻度も上げていけると思います。
まとめ
自信を持ってこの本を勧めるためにも、まずは自分がこのTODOを実践しなければと思います。
Cloud Functions for Firebase でslackへの通知を定期実行する ~その3~
前回の続き、今回が最終回です。
翻訳APIについて
翻訳APIを調べてみたところ、精度や応答時間、無料枠の広さなど様々な面から、GCPのCloud Translationが一番の候補に上がってきました。
FirebaseにはGCPの機能を簡単に扱うための拡張機能が用意されています。Cloud Translationについても、Translate Textという拡張機能がありました。
しかし、この拡張機能はFirestoreに保存した文字列を翻訳するもので、APIの形でリクエストの文字列を翻訳して返してくれるわけではないようです。そのため今回は使用を見送ったのですが、Firebaseの拡張機能自体はとても有用なものだと思ったので、別の機会で使ってみようと思います。

Cloud Translation API について
Cloud Translationには2種類のバージョンがあるのですが、料金形態はどちらも同じになっています。最初の50万文字は無料といった扱いになっていますが、正確には$10の使用クレジットが請求先アカウントに適用されます。お金がかからないというのに変わりはないのですが、請求額の見方によっては費用がかかっているのに驚く場合もあるかもしれないのでご注意ください。


BasicとAdvancedの違いについて、詳しくはドキュメントに記載されていますが、大きな違いとしてはこれらが挙げられます。
実際に使ってみる
ドキュメントに沿って以下の操作を進めていきます。
- プロジェクトの作成(既に作成している場合は選択するだけ)
- 課金の有効化
- API の有効化
- 認証を設定
今回はBasicを使うためAPIキーを取っておきます。 ここまで出来たら、あとは実際にAPIを叩くプログラムを書いていきます。 ドキュメントでは認証を環境変数に読み込ませていましたが、実際のコードを追ったところ引数にAPIキーを渡す形でも認証を通すことが出来ました。
私はfirebase functions:config [set or get]と設定ファイルで環境変数を管理するのが2ヶ所になるのを嫌った形ですが、実際にはこの変どう管理していくのが良いんでしょうか...もう少し色々触りながらベストプラクティスを見つけていこうと思います。
* A custom request implementation. Requests to this API may optionally use an * API key for an application, not a bearer token from a service account. This * means it is possible to skip the `makeAuthenticatedRequest` portion of the * typical request lifecycle, and manually authenticate the request here.
これを踏まえて、テキストとAPIキーは外から渡す前提で、コードは以下のようになりました。
import * as translateAPI from "@google-cloud/translate";
export const translateText = async (key: string,text: string) => {
const translate = new translateAPI.v2.Translate({
key: key,
});
const target = "ja";
return translate.translate(text, target);
};
まとめ
最終的にこれらを合わせて以下の機能が実現できました。
- Githubのトレンドを取得する
- descriptionを翻訳する
- その結果を毎日Slackに投稿する
今回作成したプログラムは私のリポジトリに置いてありますので、もしよろしければご覧ください。 今後もまた何か思いついたら機能を足してみようと思います。
(今考えてるのだと、カスタムコマンドで言語を与えてFirestoreに保存、その言語に絞ってトレンドをフィルタするとかですかね)