プロ野球速報的なことをするためのAPIを作った話
はじめに
先月の私は、小さいアウトプットを重ねようと決意していました。 今月の私は、手を動かしてモノ作ってるとそちらに夢中になって全くアウトプットが出来ていませんでした。
不思議です。
作ったモノ
タイトルの通り、プロ野球の試合情報(打席結果)を返すAPIです。 実際に完成したコードはこちらに置いています。
大まかなイメージとしては、以下の図のようになっております。
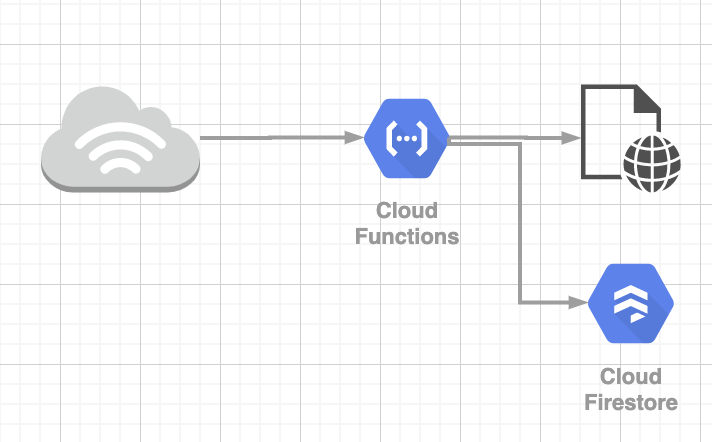
- CloudFunctionsでHTTPリクエストを受け取る
- パラメータを基にニュースサイトからスクレイピングしてデータを拝借
- 打席結果をJSONで返す
- この時、パラメータとデータをFireStoreに保存し、次回同じリクエストの際にはスクレイピングせずに保存したデータを用いる
とても恐縮なのですが、データ提供元の権利関係が怖いので、エンドポイントの方は公開しておりません。*1
一応調べたところ、robots.txt というクローラー関連の規約があるようです。
しかし、私が今回拝借したサイトにはこのファイルが置いてありませんでした。
その場合は、目安としてアクセス間隔は1秒以上空けるようにするのが良さそうです。
このアクセス間隔の制御については、API側では行っておりません。APIを呼ぶクライアント側が持つべき責務と考えたのですが、実際のところどうなんでしょうか...? この辺りの考え方はまだまだ勉強しなければと思ってます。
苦労したところ
スクレイピングについては、BeautifulSoupのライブラリがとても使いやすいのでほとんど苦労しませんでした。 一番大変だったのは、PythonでFireStoreとのデータをやり取りする部分です。
FireStoreにデータを保存する場合、基本的にDictionaryのデータ構造に整形する必要があります。このデータ構造の違いを吸収させるのが結構大変です。それなので、データクラスを作ってそのクラスにデータ変換をするto_dict の処理を任せることにしました。
@ dataclass
class Result:
team: Team
date: Date
content: Content
def to_dict(self):
dest = {
u'team': self.team,
u'date': self.date,
u'content': self.content.to_dict(),
}
return dest
また、こういったデータクラスを作るならと思い、後からFireStore以外のデータソースにも変更できるように、Repositoryパターンを使ってみました。 今回のミニマムな設計だとそこまで画期的な効果はないですが、より複雑な設計のアプリであればこういった設計力が生きてくるのかと思います。
class ResultReposiroty:
def __init__(self):
db = firestore.Client()
self.collection = db.collection('result')
def save(self, result: Result):
self.collection.add(result.to_dict())
def update(self, result: Result):
doc_id = self.collection.where(u'date', u'==', result.date).where(
u'team', u'==', result.team).get()[0].id
self.collection.document(doc_id).update({u'content.record.texts': result.to_dict()
[u'content'][u'record'][u'texts']})
def find(self, date: Date, team: Team):
docs = self.collection.where(u'date', u'==', date).where(
u'team', u'==', team).get()
return docs
まとめ
最初はGraphQLを使ってみたいと思ってたのですが、以下の理由により断念しました。
- 元々エンドポイントが一箇所なので、GraphQLの旨味が少ない
- フィールド数も少ないし、階層データも少ない
- pythonのGraphQLライブラリ
GrapheneをFireStoreと繋ぎこむのが難しい- pythonのORMモジュール
SQLAlchemyがFireStoreに対応していない
- pythonのORMモジュール
他にも、スクレイピングでテストやCIはどうするのか等々、正直途中で辞めたくなったレベルなのですが、完成させないまま投げ出すのは良くないと思いとりあえず見せれる段階までは作りました。 次作るモノは、初期設計から念入りにやっていこうと思います。
*1:個人用途で使う分には侵害にはならないようです。どこまでがセーフか分からなかったので、安全な方に倒させていただきました